
Ranking on Google page one used to be the finish line. Now there is a new game: getting your brand named as a source inside an AI-generated answer. It is a different skill set, a different playing field, and most brands have not figured it out yet. This guide gives you the exact steps.
Key Takeaways
- AI systems cite sources based on extractability and authority, not just rankings
- Structure your content into 40-60 word self-contained answer blocks that AI can lift verbatim
- Block nothing by default: allow GPTBot, PerplexityBot, ClaudeBot, Google-Extended, and Bingbot in your robots.txt
- Wikipedia is the single largest source of ChatGPT citations (7.8% of sources), followed by Reddit (1.8%) and major review sites
- Schema markup (especially Article, FAQPage, and HowTo) directly signals content structure to AI crawlers
- Third-party mentions on authoritative platforms carry more weight than self-published content alone
- A checklist of 12 concrete actions is at the bottom of this article
How AI Search Engines Actually Select Sources to Cite
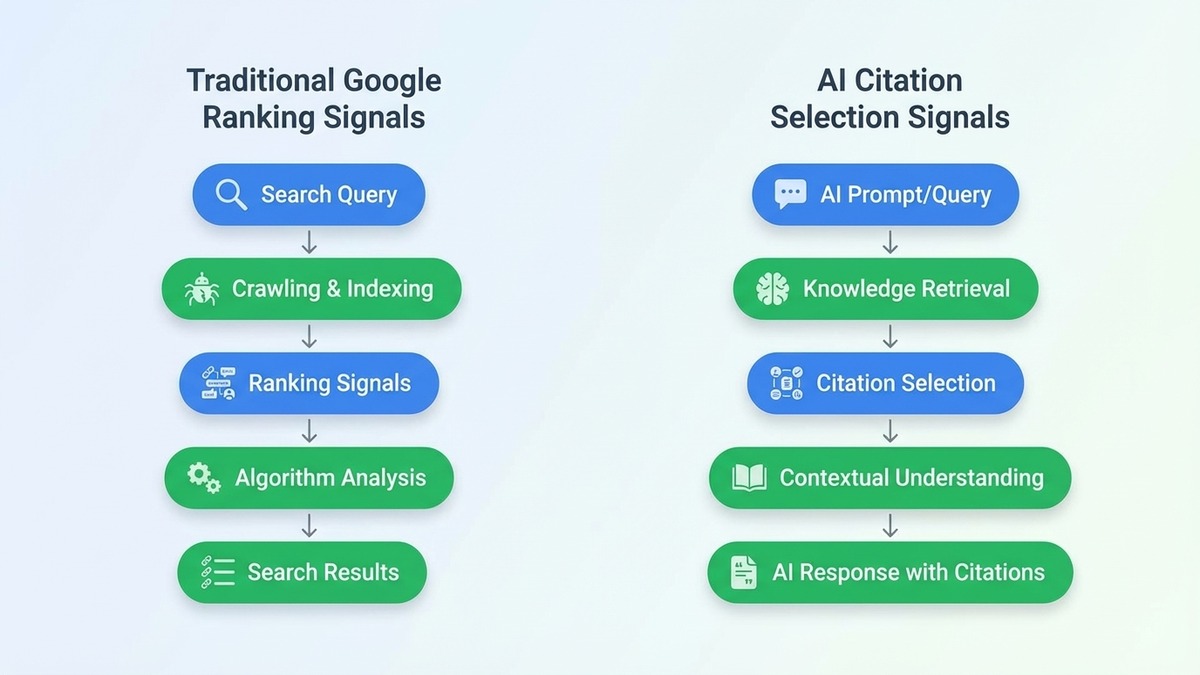
AI search engines do not rank pages the way Google does. They retrieve, extract, and synthesise. When Perplexity or Google AI Overviews assembles an answer, it is scanning for passages it can trust and reproduce accurately. A page in position 8 with a perfect 50-word answer block will get cited over a page in position 1 that buries its key point in a 600-word paragraph.
The selection process comes down to three factors:
- Crawlability. Can the AI bot access your page at all?
- Extractability. Does your content contain clear, self-contained passages that directly answer a question?
- Trust signals. Does the content appear authoritative, recent, and corroborated by third parties?
This is the core insight behind Generative Engine Optimisation (GEO): optimising not for position, but for citation. If you want a deeper breakdown of what GEO is as a discipline, read our guide on what is GEO.
The Content Structure That Gets Extracted
The single highest-impact change you can make is restructuring your content into extractable answer blocks. AI systems are designed to retrieve short, self-contained passages that fully answer a query without requiring surrounding context.
The formula: Lead every section with a direct answer in 40-60 words. No preamble. No "great question." Just the answer, stated plainly, with enough context to stand alone if pulled out of the page.
What a Bad Block Looks Like
"In this section, we will explore the many ways in which businesses can potentially improve their online visibility across various digital channels. There are numerous factors that come into play when considering..."
This is noise. An AI cannot cite it because it contains no factual claim and no direct answer.
What a Good Block Looks Like
"Perplexity cites sources based on passage-level relevance, not page authority. A 50-word paragraph that directly answers a query will outperform a 2,000-word article that buries the answer on page two. Structure each section to open with a clear, standalone answer."
That is citable. It states a claim, explains why it matters, and can be extracted without the surrounding article.
Practical rule: Write your H2 as a question, then answer it in the first paragraph. Every time.
Authority Signals AI Systems Look For
AI citation algorithms are not naive. They weight sources that exhibit trust signals consistent with expertise and accuracy. Getting cited once is luck. Getting cited consistently requires building these signals.
Statistics with Sources and Dates
Specific, sourced numbers are gold. A sentence like "AI Overviews appeared in 47% of Google searches in Q4 2025 (Search Engine Land, January 2026)" is far more citable than "AI Overviews are becoming common." Always attribute statistics. Always include a year.
Expert Quotes
Direct quotes from named, credentialed individuals add authority. If you publish research, interview, or case studies, attribute claims to real people with titles and organisations.
Freshness
AI systems, especially Perplexity and Google, heavily weight recency. Update your highest-value pages at least quarterly. Add a visible "Last updated" date at the top of the article. Perplexity, in particular, surfaces content published within the last 90 days at higher rates for news-adjacent queries.
Backlinks and Third-Party Corroboration
Pages with strong backlink profiles are more likely to be treated as authoritative sources. But backlinks alone are not enough. You also need third-party entities (other websites, platforms, social channels) saying the same things you are saying. Corroboration matters.
robots.txt: Stop Blocking the Bots That Matter
This is the most easily missed technical issue. If your robots.txt blocks AI crawlers, you will never be cited, no matter how good your content is.
The major AI crawlers to allow:
| Bot Name | Platform | User-Agent String |
|---|---|---|
| GPTBot | OpenAI / ChatGPT | GPTBot |
| PerplexityBot | Perplexity | PerplexityBot |
| ClaudeBot | Anthropic | ClaudeBot |
| Google-Extended | Google AI / Bard | Google-Extended |
| CCBot | Common Crawl (used in training) | CCBot |
| Bingbot | Microsoft Copilot | Bingbot |
Check your robots.txt now. If you have a blanket Disallow: / for all bots, or specific blocks on any of the above, you are invisible to AI. A safe default configuration:
User-agent: GPTBot Allow: / User-agent: PerplexityBot Allow: / User-agent: ClaudeBot Allow: / User-agent: Google-Extended Allow: / User-agent: CCBot Allow: /
The only legitimate reason to block a specific bot is if you have paywalled content that you do not want used in AI training. For most marketing pages and blog content, blocking AI crawlers is self-defeating.
Third-Party Presence: Where AI Pulls Citations From
Your own website is only one source. AI systems aggregate across the web, and some platforms carry disproportionate citation weight.
A 2024 analysis of ChatGPT source citations found:
- Wikipedia: 7.8% of all citations come from Wikipedia pages
- Reddit: 1.8% of citations come from Reddit threads and comments
- Review platforms (G2, Capterra, Trustpilot, Yelp): cited heavily for product and service queries
- YouTube: transcripts and video descriptions are indexed and cited for how-to queries
- Major news publications: BBC, Reuters, Forbes, and similar outlets dominate news-adjacent queries
What This Means for Your Strategy
You cannot rely on your own domain alone. You need a presence on the platforms AI trusts most.
Actionable steps:
- Wikipedia: If your brand, product category, or industry concept does not have a Wikipedia entry, create or contribute to one. Neutral, factual, well-sourced content on Wikipedia is the highest-leverage citation target on the internet.
- Reddit: Build genuine presence in relevant subreddits. Answer questions, contribute to discussions. Forced or spammy Reddit activity gets removed, but authentic participation compounds.
- Review sites: Actively solicit G2, Capterra, or Google Reviews. AI systems surface reviews for "best X" and "X vs Y" queries.
- YouTube: Publish video content and write detailed descriptions with the key answer text included. Transcripts should be accurate and keyword-relevant.
- Industry publications: Guest posts, quotes in news articles, and features in trade publications all feed the AI corroboration signal.
Schema Markup That Helps AI Understand Your Content
Schema markup does not directly cause citations, but it helps AI systems categorise and understand your content faster. Well-structured schema reduces ambiguity about what a page is about and what type of content it contains.
The three most useful schema types for AI citation:
1. Article Schema
Signals that the page is editorial content, includes an author, a date published, and a date modified. The dateModified field in particular helps AI systems assess freshness.
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "How to Get Your Brand Cited by ChatGPT, Perplexity, and Google AI",
"author": {"@type": "Person", "name": "Berenice S."},
"datePublished": "2026-03-15",
"dateModified": "2026-03-15"
}
2. FAQPage Schema
Explicitly structures question-and-answer pairs. This is one of the highest-performing schema types for appearing in AI Overviews because the format directly mirrors how AI generates answers.
3. HowTo Schema
For process-based content, HowTo schema marks up each step individually, making it trivially easy for AI to extract and sequence the information.
For a full breakdown of how schema markup interacts with search and AI, our upcoming article on schema markup for SEO covers this in depth. You may also want to read our broader look at AI and SEO to understand the landscape these tactics operate within.
Cited vs. Not Cited: Real Content Examples
The difference between cited and ignored content usually comes down to one thing: does the passage answer the question directly, or does it dance around it?
Example Query: "How long does SEO take to work?"
Not citable:
"SEO is a long-term investment. Many factors influence how quickly you might start seeing results from your SEO efforts, including things like your domain age, competition levels, content quality, and many other variables that are hard to predict..."
Citable:
"SEO typically takes 3 to 6 months to show meaningful results for a new website, and 1 to 3 months for an established site targeting new keywords. Timelines depend on competition level, content quality, and crawl frequency."
The second version makes a specific, falsifiable claim. It is short enough to extract whole. It answers the question immediately.
Example Query: "What is robots.txt used for?"
Not citable:
"Robots.txt is a file that webmasters use to communicate with web crawlers. It has many uses and has been around since the early days of the web..."
Citable:
"A robots.txt file tells search engine and AI crawlers which pages they are allowed or not allowed to access. It sits in the root directory of your website and is the first file most crawlers check before indexing any content."
Same information. Very different extraction potential.
Step-by-Step Implementation Checklist
Use this as your working list. Tick each off before considering your site AI-citation ready.
Technical Access
- [ ] Check robots.txt: confirm GPTBot, PerplexityBot, ClaudeBot, Google-Extended, and Bingbot are allowed
- [ ] Confirm your sitemap is submitted to Google Search Console and Bing Webmaster Tools
- [ ] Ensure pages load cleanly without JavaScript rendering required to see core content
Content Structure
- [ ] Every H2 section opens with a 40-60 word direct answer
- [ ] H2 and H3 headings are written as questions or match common query phrasing
- [ ] Key statistics include source name and year
- [ ] Add or update "Last updated" dates on high-value pages
Schema Markup
- [ ] Article schema implemented with author, datePublished, dateModified
- [ ] FAQPage schema added to any Q&A sections
- [ ] HowTo schema added to any step-by-step sections
Third-Party Presence
- [ ] Wikipedia: brand or category page exists or is in progress
- [ ] Reddit: authentic participation in 2-3 relevant subreddits
- [ ] Review platforms: G2, Capterra, or Google Reviews profile is active
- [ ] YouTube: at least one video with a detailed, keyword-rich description
Authority Signals
- [ ] At least one expert quote per article
- [ ] All statistics linked or attributed to primary sources
- [ ] A backlink acquisition plan is active (guest posts, PR, partnerships)
Start Getting Cited
AI citation is not luck. It is the output of deliberate content architecture, technical access, and authority building across multiple platforms. Brands that get cited consistently have made it easy for AI to find their content, trust it, and reproduce it.
If you want support building this into your content strategy, our team provides SEO copywriting services designed specifically for AI-era visibility. Or if you want to audit your current performance across traditional and AI search, our digital marketing agency in Singapore runs both together.
Get in touch with our team to find out where your brand stands and what it would take to start appearing in AI answers consistently.
